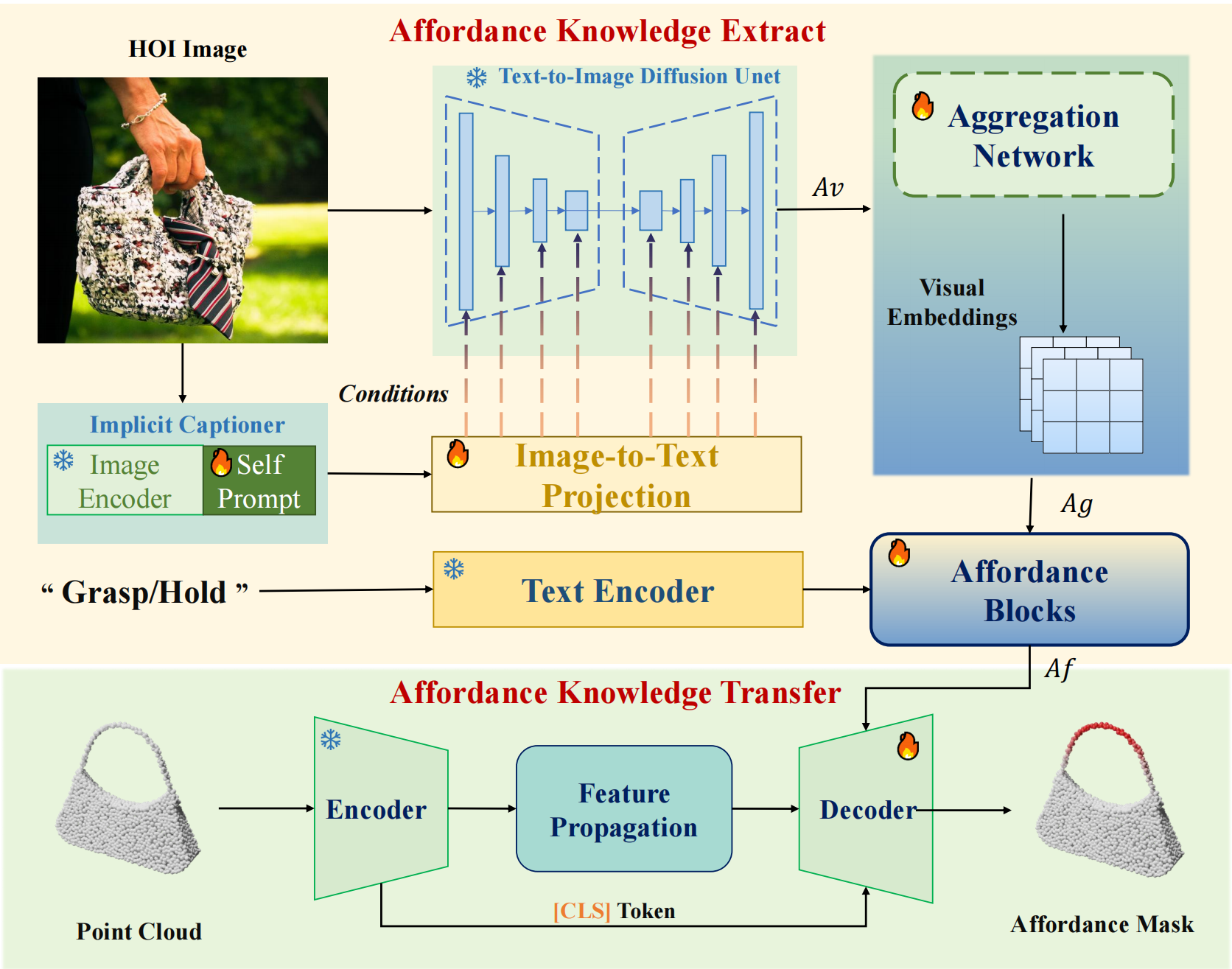
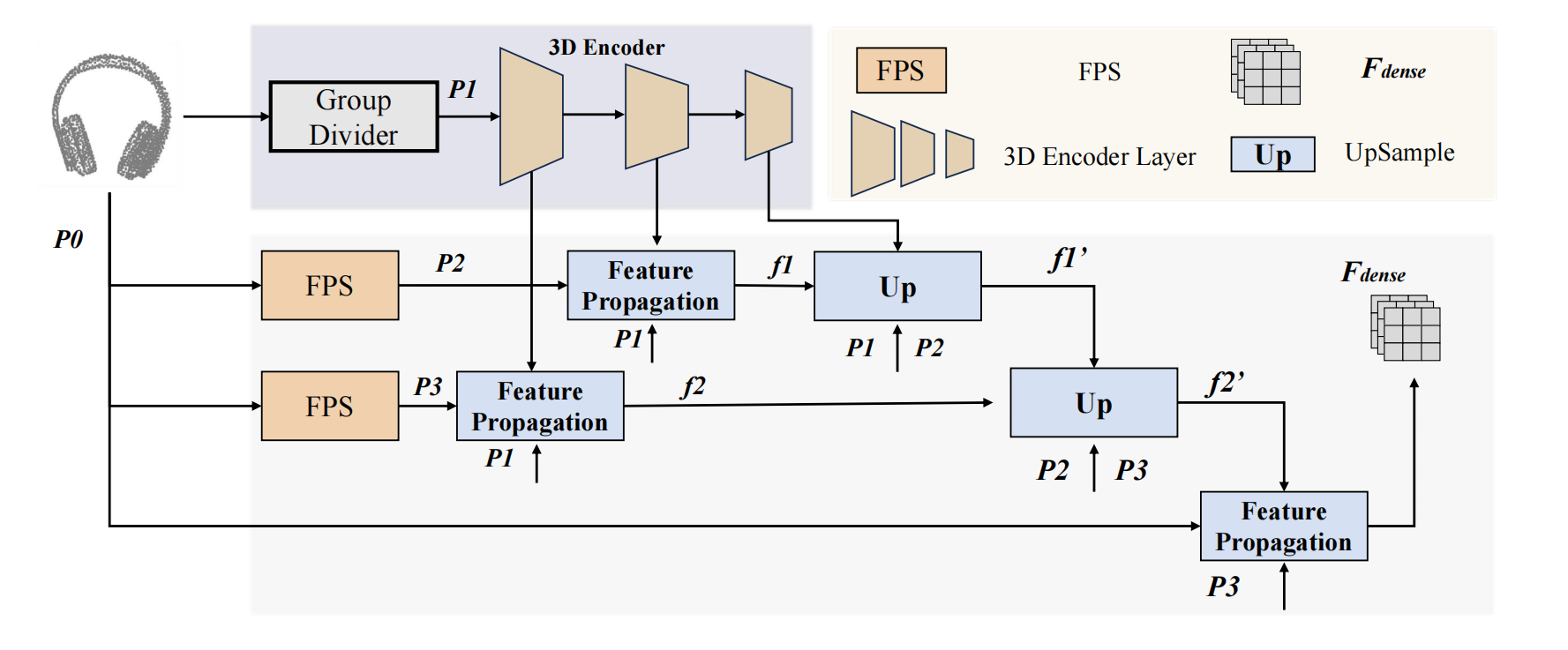
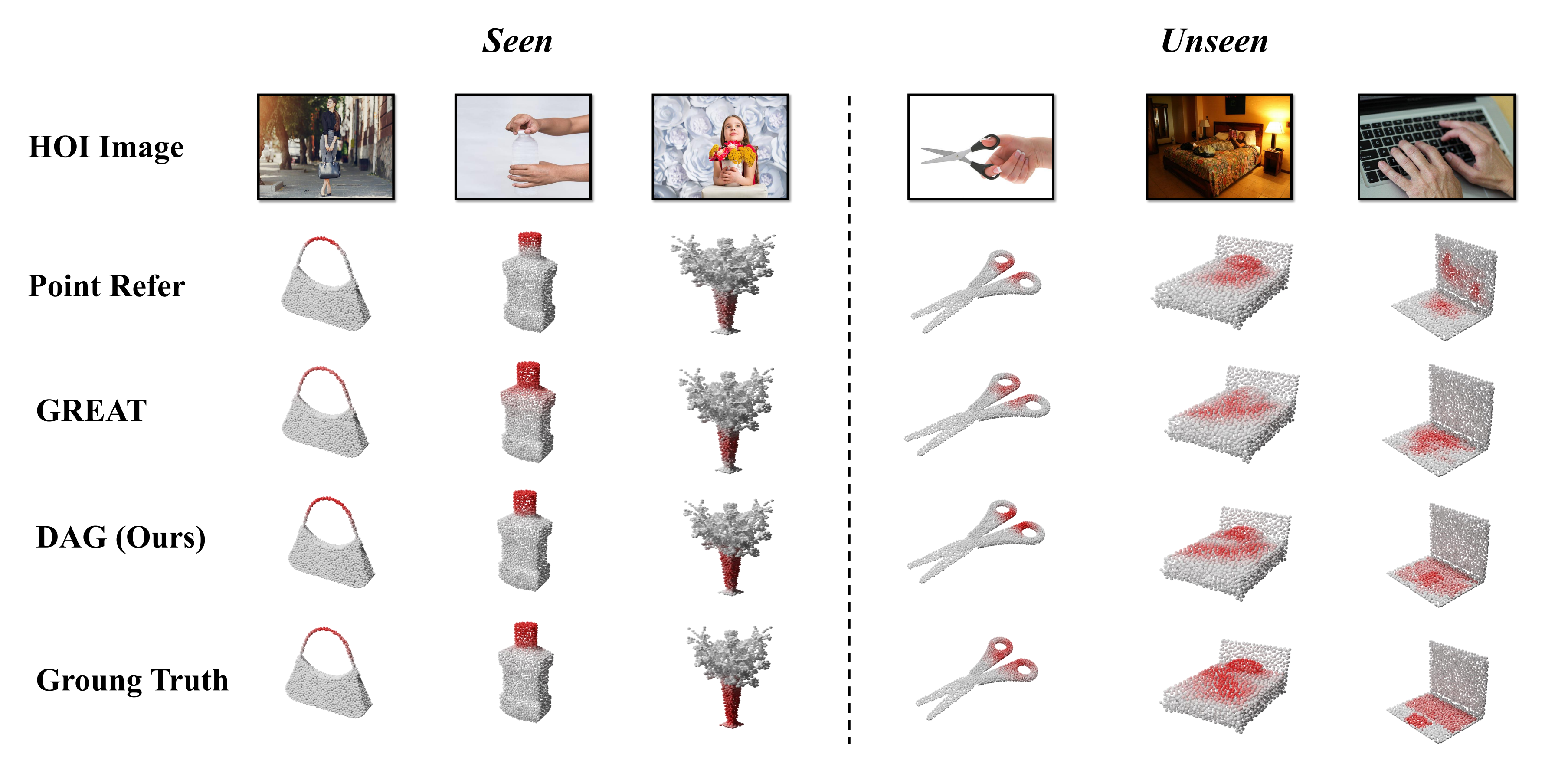
3D affordance grounding aims to understand how diverse objects can be manipulated, making it a cornerstone of embodied interaction. However, prior works struggle to generalize to out-of-distribution, open-world scenarios, leaving a critical gap between limited dataset performance and real-world application needs. Inspired by the saying: ``What I can not create, I do not understand, we find generative models can generate semantically valid HOI images, which indicates inherent encoding of affordance concepts. Building on this insight, we propose DAG, the first innovative diffusion-based 3D affordance grounding framework that extracts general affordance knowledge from text-to-image diffusion models for 3D affordance prediction. Specifically, we extract the affordance priors from a diffusion model to encode HOI priors, and design an affordance block with a multi-source affordance decoder for dense 3D affordance prediction. Extensive experiments show that DAG consistently outperforms state-of-the-art methods and exhibits strong open-world generalization, even in the challenging one-shot setting.